
「社内に蓄積された膨大な文書をAIで活用したいが、精度やセキュリティに不安がある」──こうした声を持つ企業は少なくありません。
近年注目を集めるRAG(Retrieval-Augmented Generation)は、社内ドキュメントをAIの回答根拠として活用する技術であり、大規模言語モデル(LLM)単体では実現できない「根拠に基づく正確な回答」を可能にします。
しかし、同じLLMを使っていても回答品質に大きな差が出ることがあります。その差を生むのは、LLMそのものではなく「どの資料を、どの順序で、どれだけ正確にLLMに渡すか」というRAGパイプラインの品質です。
DirectCloud AIは、この前段の仕組み──文書解析(パース)、意味単位での分割(チャンキング)、検索(リトリーバル)、そして回答生成──に至る全工程の精度向上に取り組んでいます。
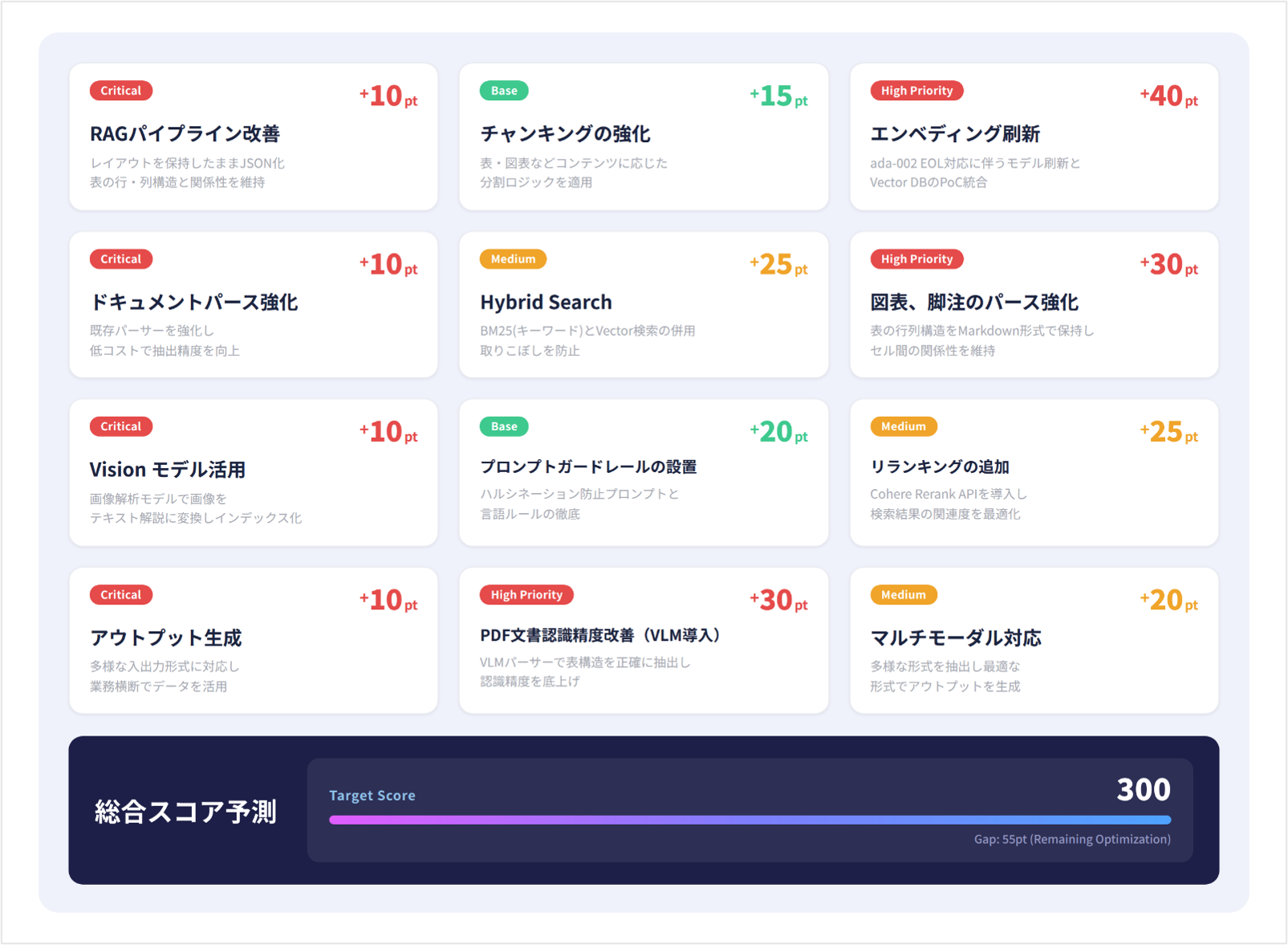
< 高精度なRAGを実現するための各種施策 >
なぜDirectCloud AIなのか。それは、ファイル管理基盤との統合による閉域運用と、RAG全工程を自社で最適化できる設計力にあります。
本コラムでは、その技術的基盤と今後のロードマップを詳しくご紹介します。
本記事のサマリ
-
 DirectCloud AIはRAGの全工程を改善することで、回答精度の向上を実現している
DirectCloud AIはRAGの全工程を改善することで、回答精度の向上を実現している
-
RAGパイプライン改善やパース強化、Visionモデルの活用、アウトプット生成により、図表を含む文書の読み取り精度を高め、多様な形式でのファイル生成にも対応している
-
閉域RAGアーキテクチャにより、データ流出リスクを排除し、安全な社内文書のAI活用を支援している
DirectCloud AIの技術的基盤——文書理解の精度を根本から高める
RAGの回答精度を左右する最大の要因は、LLMに渡す「検索結果の質」です。
ChatGPTやPerplexityのようなAIサービスは、「パース」から「回答生成」に至るまで、多層的なパイプラインを備えています。
一方、自社で構築するRAGでは、パースの精度、チャンキングの適切さ、エンベディングの品質、権限管理や最新性といった各工程を一つひとつ丁寧に作り込む必要があります。
したがって、回答の良し悪しは、LLMの差よりもパイプラインの品質差に依存します。
参考:「動くRAG」と「使えるRAG」は違う:企業運用で成果を出す品質と継続性を備えた”高品質RAG基盤”の条件
DirectCloud AIでは、この検索品質を根本から高めるため、4つの施策を軸に開発を進めています。
-
●RAGパイプライン改善
レイアウトを保持したJSON変換や表の行列構造維持により、構造的情報の欠損を防止します。
-
●ドキュメントパース強化
既存のパーサーの改良を通じ、低コストで表構造の抽出精度を向上させます。
-
●Visionモデル活用
画像や図表をテキスト解説に変換しインデックス化することで、ビジュアル情報も検索対象に含めます。
-
●アウトプット生成
多様な形式での入出力に対応し、業務横断でのデータ活用を可能にします。

< DirectCloud AIのアーキテクチャ >
これら4つの施策を進める理由は、回答品質の土台となる「文書の正確な読み取り」が、すべての出発点だからです。
企業文書に多い図表・画像といった情報は、従来のRAGでは正しく処理できず取りこぼされてきました。
DirectCloud AIはこの課題に正面から向き合い、解析エンジンの使用する言語をGoからPythonへ全面移行し、以下の幅広いファイル形式を網羅的にカバーしています。
- ●PDFファイル(pdf)
- ●文書ファイル(docx、pptx※、hwp※)
- ●表計算ファイル(csv※、xlsx※)
- ●電子メールファイル(eml、msg、mbox)
- ●テキストファイル(txt)
- ●データファイル(json)
※今後のアップデートで対応予定
文書解析・検索精度を高める技術基盤 – RAGパイプライン改善
DirectCloud AIでは、文書解析と検索精度を高めるために、RAGのパイプラインを改善しています。
企業文書は、本文、表、脚注など複数のコンテンツタイプが混在しており、それぞれに適した処理を行わなければ、RAGの精度は安定しません。
この課題に対し、チャンキング、エンベディング、検索方式の各工程を見直すことで、文書理解から検索までの精度向上を図っています。
チャンキングの強化
チャンキングとは、長文ドキュメントをAIが検索・参照しやすい単位に分割する前処理技術です。
分割の精度が低い場合、文脈が途切れ、回答品質の悪化につながります。
今回、コンテンツ構造を理解したうえで、意味のまとまりごとに分割する手法を導入し、検索精度の大幅な改善を実現。
-
① 課題
従来の固定長での分割(800文字区切り)では、図表や脚注などのコンテンツが文脈ごと分断され、検索精度の低下を招いている。
-
② 対策
チャンキング精度の強化により、図表・脚注などコンテンツタイプに応じた分割ロジックを適用。
また、隣接文章間のコサイン類似度を測定し主題の転換点を検出する「セマンティックチャンキング」や、図表・数式を独立チャンクとして分離する専用処理も導入。 -
③ メリット
文書の目次、セクション構造を認識し、関連する条項をひとつのチャンクとして維持することで、検索精度が約15%向上し、文脈の分断を最小限に抑えることに成功。
エンベディング刷新
現行のEmbeddingモデル「ada-002」のサポート終了に伴い、DirectCloudはベクトルモデルを高性能な新モデルへ刷新する予定です。
意味的マッチング精度の向上に加え、セマンティックキャッシングの導入により、LLMコストの大幅削減と応答速度の改善が期待されます。
-
① 課題
現行のEmbeddingモデル ada-002がサポート終了(EOL)を迎えるため、早急なモデル移行が必要な状況。
さらに、現状のベクトル検索では意味的マッチングの精度に限界があり、ユーザーの質問意図に合った文書が上位に表示されないケースが発生。 -
② 対策
意味的マッチング精度に優れた高性能なベクトルモデルに刷新予定。
意味的に類似した質問に対してはLLMを経由せずキャッシュ済みの回答を返す「セマンティックキャッシング」の導入を検討中。 -
③ メリット
新モデルへの移行により、文書とクエリの意味的マッチング精度が向上。 Vector DBとの統合PoC(概念実証)を通じて、質問の意図に合致した文書が上位に表示される確率が大幅に改善される予定。
LLM呼び出しコストが最大86%まで削減されることで、応答速度が大幅に改善される予定。
Hybrid Search
キーワード検索とベクトル検索にはそれぞれ弱点があり、単独運用では検索精度に限界がありました。
DirectCloud AIでは、この課題に対してHybrid Searchの採用により対応しています。
キーワード検索と、ベクトル検索の強みを組み合わせることで、より精度の高い文書検索を実現しています。
-
① 課題
キーワード検索(BM25)とベクトル検索を単独で運用の際、それぞれ異なる弱点が存在。
キーワード検索は同義語に弱く、ベクトル検索は固有名詞の完全一致に劣り、検索精度には限界がある。 -
② 対策
DirectCloud AIではキーワード検索とベクトル検索を併用するHybrid Searchを採用。OpenSearch 2.19のRRF(Reciprocal Rank Fusion)で双方のランキングを統合。
-
③ メリット
キーワードの取りこぼしを大幅に削減し、検索精度が向上。
今後の開発計画としては、重み付けチューニングとフィルタリング高度化により、さらなる精度向上を予定。
文書の読み取り精度を高める技術基盤 – ドキュメントパース強化
DirectCloud AIでは、RAGの回答品質を安定させるために、文書の読み取り精度そのものを高める取り組みを行っています。
検索や生成の精度を高める以前に、文書の内容を正しく理解できなければ、実務で信頼できる回答は得られません。
特に企業文書では、表形式の情報や定型表現が多く、これらを正確に扱うためのドキュメントパース強化が重要な技術基盤となります。
図表、脚注のパース強化(Unstructured、MarkItDown)
従来の文書解析では、企業文書に多用される表のセル構造が崩壊し、AIが正確な情報を参照できない課題がありました。
今回のアップデートにて改善されたパース強化により、表の行列構造をMarkdown形式で正確に保持し、表内のピンポイント検索にも対応できるようになりました。
DirectCloud AIでは、ファイル形式ごとに最適なパーサーを採用しており、文書ファイル(docx)にはMarkItDown、PDFファイルにはレイアウト認識に特化したUnstructuredを導入しています。
-
① 課題
従来の文書解析エンジンでは、企業文書で頻出する表形式のデータ構造が崩壊し、セル間の関係性が完全に失われていた。
-
② 対策
表の行列構造を正確に認識しMarkdown形式で保持。ヘッダーとデータの対応関係を維持したまま検索用インデックスに格納。
PDFファイルには、表・図・段落構造を高精度に抽出するレイアウト認識特化のパーサー「Unstructured」を採用。 -
③ メリット
「○○の数値はいくつか」といった、表内ピンポイント検索にも正確に回答可能。
PDFファイルの表パースではページ境界をまたぐ表にも対応。
文書ファイル(docx)では表・脚注・数式の構造を保持したまま処理が可能になった。
■具体的な導入効果については、以下を参照
https://directcloud.jp/contents/update-2026-03
プロンプトガードレールの設置
業務でAIを活用する上で最大のリスクとなるハルシネーション(根拠のない情報を「もっともらしく」生成)や、社内文書に潜む悪意ある指示文による間接プロンプトインジェクションを抑制するため、DirectCloud AIでは入力・検索・出力の3階層にわたる多層ガードレールを導入しています。
根拠付き回答率95%以上を目標に、回答品質の継続的な向上を図っています。
-
① 課題
LLMが検索根拠にない情報を「もっともらしく」生成してしまうハルシネーション(幻覚)は、業務利用における最も深刻なリスクとなっている。
さらに、社内文書そのものに悪意ある指示文が埋め込まれ、それを検索・参照する過程でAIの挙動が乗っ取られる「間接プロンプトインジェクション」も、社内RAG特有のリスクとして無視できない。 -
② 対策
ハルシネーションに加え、社内文書に潜む悪意ある指示文による間接プロンプトインジェクションなど、社内RAG特有のリスクに対応するため、入力・検索・出力の3階層にわたる多層ガードレールを導入。
・入力ガードレール:ユーザーのクエリ時点でプロンプトインジェクションやjailbreakの試行を検知し、トピック逸脱を遮断。
・検索ガードレール:RAGコンテキストに入る文書内の悪意ある指示文を無力化し、社内文書を経由した間接攻撃を遮断。
・出力ガードレール:ハルシネーション防止プロンプトと言語ルールを徹底し、「検索した情報の中から根拠のある情報のみで回答する」ことを厳格に制御。あわせて、有害表現のフィルタリングや引用・フォーマットの整合性検証を実施。
今後の機能評価として、質問の意図と回答の適合度を測る自動評価フレームワーク(Ragas/DeepEval等)の導入も予定。 -
③ メリット
根拠付き回答率(Grounded Answer Rate)95%以上を目標とし、回答には必ず参照元の文書名とページを明示。
自動評価フレームワークの活用により、品質管理の継続的な強化に貢献。
リランキングの追加
ベクトル検索で取得した文書が、質問意図と必ずしも一致しない課題に対し、DirectCloud AIはAWS Bedrock上のCohere Rerankを導入します。
検索結果を関連度で再評価することで、回答精度のさらなる向上に貢献します。
-
① 課題
検索が持つ課題として、検索で上位に取得した文書が、必ずしも質問に対する最適な根拠とはならない。
初期検索の順位はあくまで類似度スコアであり、質問意図との適合度は別途評価が必要。
さらに、従来選別を担っていた外部のCohere SaaSには、検索クエリや文書内容が国外のSaaSへ送信される、レート制限によりトラフィック増加時に処理が詰まる、既存のAWS基盤と別系統になりセキュリティ境界の管理が煩雑になる、といった運用上の課題があった。 -
② 対策
選別段階を担うRerankerを、外部のCohere SaaSからAWS Bedrock上のCohere Rerank 3.5に置き換え、検索結果を質問との関連度でリランキング。
AWS内部(Japanリージョン)でのみ処理し、IAM/VPC/PrivateLinkを通じてセキュリティ境界内で呼び出すことで、国外へのデータ転送をゼロにし、既存のAWS基盤と自然に統合。
(※上位5件に正答根拠が含まれる「Retrieval Hit Rate@5」を85%以上に引き上げることが目標。) -
③ メリット
検索の「最後の仕上げ」として回答精度を底上げし、実測のPairwise Win Rateはベクトル検索のみの約30%から約55%へ向上。
外部SaaSと同等の精度を、国外へのデータ転送やレート制限のリスクなしで実現し、セキュリティと精度を両立。
PDF文書認識精度改善(VLM導入)
RAGの回答精度は、その起点となる文書のパース(読み取り)の正確さに大きく左右されます。パーサーが表や数式を誤読すると、後段の検索や生成がどれほど高度でも、正確な回答にはつながりません。
DirectCloud AIでは、従来の複数モデルを組み合わせた解析方式から、ページ画像を直接解釈するEnd-to-End方式のVLM(Vision Language Model)パーサーへ移行し、図表・数式・多言語が混在する難易度の高い文書でも認識精度を底上げします。
-
① 課題
RAGパイプラインの起点は文書のパースであり、パーサーが文書を誤読すると、後段のAIがどれほど優秀でも誤った回答しか生成できない。
既存のunstructuredライブラリは複数モデル(YOLOX+table-transformer+Tesseract OCR)を順次実行する構成のため、メモリ使用量の急増によるサーバーダウン、英文基準の処理に起因する日本語・数式の誤認識、技術世代の古さといった課題があった。 -
② 対策
文書パーサーをEnd-to-End方式のVLMパーサー(GPT-5.4)へ転換。ページ画像を直接解釈させることで、表構造をMarkdownテーブル形式のまま保持し、各項目の値を行単位で正確に抽出・引用できる形に変換。
(※図表やマトリクスが密集する文書において、回答の正答率を示すAnswer Passを29%から59%(+30pp)の水準まで引き上げることを目標) -
③ メリット
パイプラインの最上流である文書認識を底上げすることで、後段のすべての工程の精度向上に波及。特に図表・数式・多言語が混在する難易度の高い文書ほど効果が大きい。
「関連内容が見つかりませんでした」で終わっていた表ベースの質問にも、具体的な数値を引用して回答できるようになり、ユーザーの体感品質が大きく改善。
画像の読み取り精度を高める技術基盤 – Vision モデル活用
画像のパース強化
グラフやフローチャートなど、社内資料に含まれる図表は従来のRAGでは検索対象外でした。
DirectCloud AIは、Visionモデルを活用して図表をテキスト化、インデックス化することで、視覚情報に基づく質問への回答を可能にします。
-
① 課題
グラフ、フローチャート、写真付き手順書など、テキストだけでは表現しきれない情報が、社内資料に多数存在。
従来のRAGでは、これらの図表が完全に検索対象外となっており、活用ができない状態。 -
② 対策
DirectCloud AIでは、Visionモデルを活用して図表の構造を認識し、テキスト解説に変換してインデックス化するPoCを推進中。
-
③ メリット
OCRと画像認識を組み合わせにより、図表をテキストデータとして検索が可能。
「この図に示されている改善効果は?」といった視覚情報に基づく質問にも対応可能。現在開発中。
多様な形式での出力を可能にする技術基盤 – アウトプット生成
マルチモーダル対応
業務で扱う情報は、テキストだけでなく表・画像・システムログ・メールなど多様な形式に分散しています。形式ごとに別ツールや手作業での変換が必要だと、AI活用の効果は頭打ちになりがちです。
DirectCloud AIは、多様なファイル形式からのデータ抽出と、用途に応じた最適な形式での出力に対応することで、入力から成果物の生成までを一気通貫で支援します。
-
① 課題
業務で扱う情報はテキストだけでなく、表・画像・システムログ・メールなど多様な形式に分散しており、横断的に活用しづらい。
AIに渡せる入力形式や受け取れる出力形式が限られると、結局は人手による前処理や清書が発生し、自動化の効果が頭打ちになる。 -
② 対策
Office文書やPDFをはじめ、CSV、画像、Eメール(EML)、JSONなど、多様なファイルから必要なデータを自動で抽出。
お客様の要望に合わせて、Markdown、HTML、PowerPoint、画像など、最適な形式でアウトプットを生成する。 -
③ メリット
データ集計の自動化:システムのログデータ(JSON/CSV)を読み込ませるだけで、月次の利用状況をまとめた表やグラフを瞬時に作成。
資料作成の効率化:顧客の要望書や社内の仕様書・カタログをもとに、提案書のラフ(PowerPoint構成案)を自動で構築。
セキュリティと閉域運用——社内文書だからこその安全設計
権限統制の継承
DirectCloud AIが参照する情報源は、DirectCloud内で管理されたファイルに限定されます。ユーザーごとのアクセス権限やファイル管理ポリシーは、DirectCloud AIの参照範囲にもそのまま適用されます。
- ●参照対象はDirectCloud内の管理ファイルのみ
- ●ユーザーごとのアクセス権限をDirectCloud AIの参照範囲にも継承
- ●ファイル管理ポリシーの変更は即座にDirectCloud AI側へ反映
これにより、「特定部署の社員だけが閲覧可能な文書」がDirectCloud AI経由で他の社員に共有されることはありません。権限管理の一貫性が、組織内の情報漏洩リスクを構造的に抑制します。
推論処理の透明性
回答生成処理の一環で、検索クエリと参照文書の一部がMicrosoft Azureのエンタープライズ向け環境へ送信されます。一方、検索結果のリランキング処理はAWS(Japanリージョン)内で完結し、国外へのデータ転送は発生しません。
- ●回答生成の送信先はMicrosoft Azureのエンタープライズ向け環境
- ●リランキングはAWS(Japanリージョン)内で処理し、国外へのデータ転送は発生しない
- ●送信データはモデルの再学習には利用されない
- ●回答生成とリランキング処理のために必要な範囲に限定
より厳格な情報管理要件にお応えするため、処理リージョンの固定やPrivate Endpointによる限定接続を含むエンタープライズ構成の拡充も検討しています。
処理状況を可視化するUX
DirectCloud AIの処理状況を「検索中」「構想中」「プレゼンテーション資料作成中」などに分けてリアルタイムに可視化するUXの導入も2026年内に予定しています。
ユーザーがDirectCloud AIの思考過程を追跡でき、回答を待つ間の不安を解消するとともに、処理のどこに時間がかかっているかを把握できるようになります。
まとめ
DirectCloud AIのRAG改善は「精度・安全・信頼性」の3軸で進行しています。パースの強化とチャンキングの強化で文書理解の土台を固め、Hybrid Searchとリランキングで検索精度を引き上げ、プロンプトガードレールの設置でハルシネーションを抑制します。さらに、アウトプット生成(マルチモーダル対応)により、多様な形式での入出力にも対応しています。
この一連の取り組みにより、同じLLMを使っていても「的確な根拠に基づく回答」が返ってくる仕組みを構築しています。
今後は2026年内のベンチマーク(Targetスコア300pt)達成に向けて、Visionモデルの本格導入やエンベディングの刷新をさらに加速させます。
品質評価についても、Retrieval Hit Rate@5(85%以上)、Grounded Answer Rate(95%以上)、Answer Correctness(3.5/4以上)といった定量KPIに加え、実業務シナリオでの定性評価を組み合わせた、2軸管理を導入予定です。
DirectCloud AIは、「パースの精度向上」「検索アルゴリズムの最適化」「回答生成の品質管理」といったRAGの全工程における継続的な進化を通じて、企業の社内文書のAI活用を強力に支援してまいります。
「まずは社内文書でRAGを試したい」とお考えの方は、ぜひお気軽にお問い合わせください。
よくある質問(Q&A)
- なぜDirectCloud AIではRAGの改善を継続的な取り組みとして位置付けているのですか?
-
企業文書の形式や内容は継続的に変化するため、一度構築したRAG基盤だけでは精度を維持できません。
DirectCloud AIでは、評価指標をもとに改善を重ねることで、長期的に安定した回答品質を確保しています。 - 現在利用しているファイルをDirectCloud AIで活用する際、特別な準備や変換作業は必要ですか?
-
特別な変換作業は不要です。
多様なファイル形式に対応しており、DirectCloudにファイルを格納するだけで自動的に解析・インデックス化されます。 - DirectCloud AIのRAGは、他社のRAGソリューションと比べてどのような点で差別化されていますか?
-
ファイル管理基盤との統合による閉域運用と、パースからリランキングまでのRAG全工程を、自社で最適化できる設計力が最大の差別化ポイントです。
外部クラウドへのデータ流出リスクを構造的に排除しながら、精度改善を継続的に積み重ねられる体制を持っています。 - 専任のIT担当者がいない中小規模の企業でも、DirectCloud AIのRAGを運用できますか?
-
パーサー刷新やインデックス化は自動で処理されるため、技術的な専門知識がなくても運用可能な設計となっています。
また、AIの処理状況をリアルタイムに可視化するUXの導入により、担当者がAIの動作を直感的に把握できるため、専任の情報システム担当がいない企業にこそ、最適なソリューションです。



